
作为开源大模型的顶梁柱,Llama3正在遭遇冷落。
近日,据美国媒体The Information报道,Llama在全球最大的云计算服务供应商亚马逊的AWS平台上备受冷落,与之相对,Anthropic的闭源模型Claude才是该平台上最受欢迎的模型。报道称,在另一家云平台微软Azure上,Llama也并非微软的销售首选。

一个月前,Meta发布了最新的开源大模型Llama 3.1 405B,在测试中性能追平GPT-4o。可惜,测评中的优异成绩没能反映在市场上,据报道,Llama3.1上线一个月后,下载量仅为360万,比上一代模型降低了40%。
门槛高效率低,开源模型“才是最贵的”
这一现象早有预兆。早在今年4月,Llama 3推出70B和400B模型之后,就有开发者反馈“免费的才是最贵的”,Llama 3“根本用不起”的现象。
当时,一位美国AI创业者Arsenii Shatokhin的采访视频在网上流传,这位创业者表示,“我们只有一两个客户有足够资源,来精调或运行700亿参数的Llama开源模型。”

访谈中,这位AI智能体公司VRSEN的创始人指出,企业自己运行开源大模型的效率远低于使用闭源大模型。他分析出两个原因:
1) 首先,开源模型多数需要企业自己下载后运行,随着模型参数向百亿、千亿不断攀升,对本地IT设施要求也随之提高,大量企业并不具备与之匹配的充足资源;
2) 其次,与做好精调和商业化适配的闭源模型不同,如果使用开源模型,企业还要再做优化,需要公司内部有足够的技术人才和技术设施,对企业的技术能力无疑是提出了更高要求。
“我们只会向具备数据专业知识的客户推销Llama,比如内部有工程师和数据科学家的公司。”据The Information报道中,微软员工这样向媒体表示。
正如百度创始人李彦宏在近期的上海世界人工智能大会上表示,开源模型在学术研究、教学领域有一定价值,能够让学术界更熟悉大模型的工作机制、形成理论;但在大多数的应用场景中,开源模型并不合适,尤其是在激烈的商业化竞争中,只有闭源模型,才能让企业的业务效率更高、成本更低。
缺乏商业验证,开源模型将越来越落后
近期,开源和闭源模型之争一直备受行业关注,尤其是在时时更新的“测评跑分”上,每当新一代大模型诞生、领跑测评榜时,就会爆出“开源大模型超越闭源”或“闭源大模型保持领先”的各类说法。
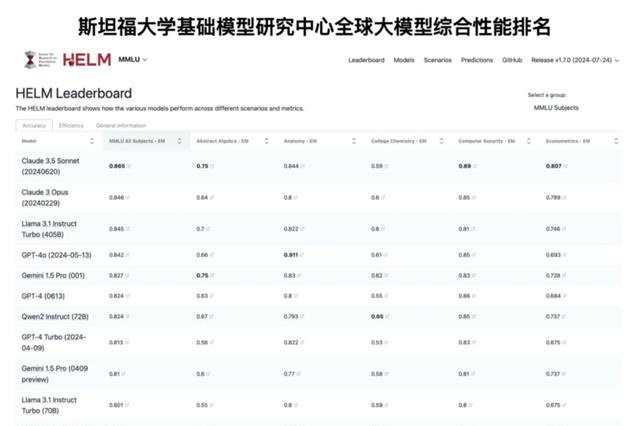
但迄今为止,闭源模型性能整体领先于开源。在斯坦福大学7月公布的大规模多任务语言理解 (MMLU)测试排名中,排名前十的模型中,仅有Llama 3.1为开源,其余9款上榜模型均为闭源。
某种程度上,这与开源模型并非“真开源”有关。有多位开发者表示,当前的开源大模型并非与开源软件不同,仅仅是开放了参数和调用接口,在使用中既存在需要SFT精调、优化的问题,还无法像真开源的Linux那样看到底层代码。
因此,大模型的开源并不能带来模型效果的提高。“开源模型和闭源模型相比,存在性能差距,这种差距将继续扩大。”谷歌前CEO施密特在采访中指出。据介绍,谷歌投资的法国Mistral公司此前推出过开源模型,但从今年2月起,已经转向了闭源模型。
在实用性方面,伴随着Llama 3的“叫好不叫座”,开源模型更是与闭源模型拉开了差距。有多位开发者表示,大模型的进步与实际应用密不可分,只有真实应用才能不断为模型提供反馈,让模型在响应速度、参数大小等方面不断优化。
随着商业化的失速,缺乏商业验证的开源模型,势必会逐步掉队。